Probability Theory and Bayes’ Theorem
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (15,3)Exercise 1: What view of probability is more appropriate?¶
Decide whether you would rather use a frequentist or a Bayesian understanding of probability to answer the following problems:
a) A medical researcher wants to determine the exact rate of prostate cancer for males between 50 and 60 in Switzerland.
Frequentist approach could be used here, divide the number of cancer cases by the male Swiss population between 50 and 60, seeing cancer as a Bernoulli experiment and treating all individuals equally. We will see next week that this can also be formulated as a continuous problem from a Bayesian viewpoint.
b) A gambler goes into a casino and looks for the game with the highest probability of winning money.
There is not much subjectivity in games and games are highly repeatable experiments, so a Frequentist view can be preferred. This would of course be different if the rules of the games were not known beforehand.
c) A poker player wants to create a mathematical model that predicts the moves of his opponents. He knows the strategies of most of his opponents quite well.
Frequentist statistics cannot incorporate prior information, so a Bayesian view is preferred here.
d) A particle physicist has run an interesting experiment. Now she wants to assess whether the collected data puts the standard model of particle physics into question. From her education she knows that a long series of experiments have confirmed the standard model.
Frequentist models can only be used to assess the probability of data under a hypothesis. In principle, the physicist could check how probable her data are under the assumption of the standard model and reject this null hypothesis when a sufficiently small p-value is reached. This can be dangerously misleading, as unlikely data could also have been produced by a faulty experiment. It’s better to choose a Bayesian viewpoint and to assess the probability (plausibility, degree of belief in) of the standard model or an alternative hypothesis and take into account the prior belief that her small experiment might not be enough to challenge an established and well-tested theory.
e) An insurance company wants to estimate the number of car accidents per year in their portfolio to guess what reserves that they have to put aside.
Car accidents can be seen as a repeatable random experiment and a Frequentist view can be assumed. However a Frequentist approach can only take into account historical data (e.g. observing and modelling a trend in car accidents) and not other expert-level data, such as the introduction of new laws (e.g. stronger tests of older people).
f) An economist predicts inflation rates in different countries for next year.
While historical data might be of some use in the prediction of inflation rates, they are probably mostly driven by expert knowledge about markets, conflicts, etc, so a Bayesian approach might be preferred.
g) A doctor is asking himself whether you could have scabies.
The doctor has assessed your symptoms (data) and can ask himself two different questions: What is the probability P(symptoms|scabies) that wou would have these symptoms given you have scabies? Are there infections or diseases with a higher probability for this symptoms? (Frequentist view) Under a Bayesian view, he could directly evaluate P(scabies|symptoms), a degree of belief in that you have scabies. The latter is much more straightforward.
h) An engineer is in charge of a production process producing thousands of special screws throughout a day. Her boss asks her to give an estimate of the rate of defective screws.
Producing a large amount of screws is a highly repeatable experiment, so a Frequentist view (uncertainty is in the object) could be preferred. However, if only an extremely small number of screws is actually defective (say one in a million), then the Bayesian viewpoint might perform better because its abilities to deal better with few-sample situations.
Exercise 2: The law of large numbers¶
The law of large numbers states that a relative frequency will stabilize in the limit of large numbers (respectively infinitey). Write a short numpy code that simulates coin tosses and computes the cumulative relative frequency at each subsequent coin toss. Visualize this cumulative relative frequency. Does your simulation stably reach 0.5 in the limit of large ? How large does approximately need to be to reach at least three zeros behind the 0.5? (or three nines behind the 0.4) .
Simulate coin tosses:
N_tosses = 1000
tosses = np.random.randint(2, size=N_tosses)
tosses[:20]array([0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 0, 1])Compute cumulative relative frequencies (aka frequentist probabilities):
cum_tosses = np.arange( 1, N_tosses+1, 1)
probs = np.cumsum( tosses ) / cum_tosses
probs[:20]array([0. , 0.5 , 0.33333333, 0.25 , 0.2 ,
0.33333333, 0.42857143, 0.5 , 0.44444444, 0.5 ,
0.54545455, 0.58333333, 0.61538462, 0.57142857, 0.6 ,
0.5625 , 0.58823529, 0.61111111, 0.57894737, 0.6 ])Final probability:
probs[-1]0.52Visualize:
plt.figure( figsize=(15,3) )
plt.plot( cum_tosses, probs, lw=2 )
plt.xlabel("tosses", fontsize=20)
plt.ylabel("P(heads)", fontsize=20)
plt.axhline(0.5, c="black", lw=1, ls="--")
plt.show()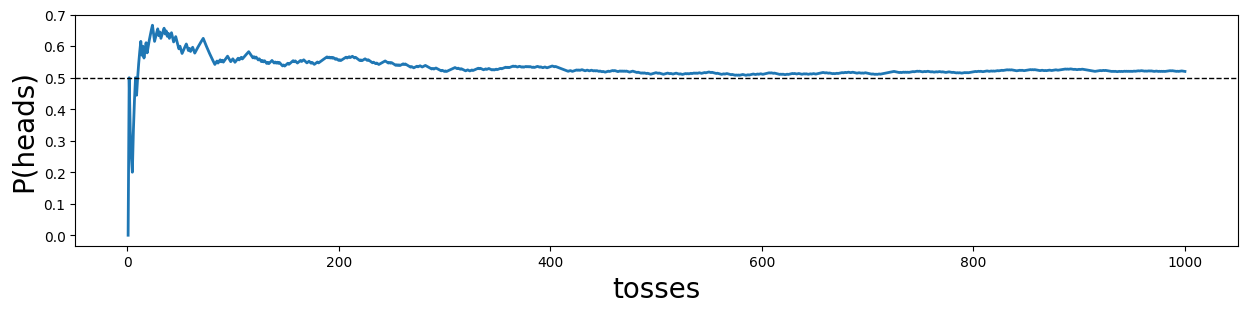
probs[-1]0.52As you can find out with trial and error, to reach more or less stably a 0.5000 or 0.4999, around Million coin tosses are needed! This can also be justified approximately by looking at the formula for the variance around :
Then the standard deviation is
which is approximately for :
np.sqrt(0.5 * (1-0.5) / 10**8)5e-05A bit less than 10^{-4} to keep the first four digits stable!
Exercise 3: Binomially distributed random variables¶
A manufacturing company produces small pumps that go into ship motors. Your boss claims that they have estimated the rate of defect pumps to be . The company produces 20 pumps per day. To compute probabilities of different daily outcomes for the number of broken pumps , you may use the binomial distribution:
You may use Python to give your answers! (e.g. with scipy.stats.binom).
a) What is the probability that exactly 5% of the pumps are defective on a production day? Try to compute your answer also in plain Python (using math.comb() for the binomial coefficient).
In plain Python:
from math import comb
pi = 0.05
n = 20
k = 1
prob = comb(n,k) * pi**k * (1-pi)**(n-k)
prob0.37735360253530725With scipy.stats.binom:
stats.binom.pmf(n=20, k=1, p=0.05)0.3773536025353076437.7%!
b) Draw the probability mass function for the number of defective pumps per day with a bar plot.
krange = range(21)
pmf = [stats.binom.pmf(n=20, k=k, p=0.05) for k in krange]
pmf[0.35848592240854227,
0.37735360253530764,
0.1886768012676542,
0.05958214776873284,
0.013327585685111271,
0.002244646010124004,
0.0002953481592268431,
3.1089279918615075e-05,
2.658951571986811e-06,
1.8659309277100433e-07,
1.0802758002531833e-08,
5.168783733268817e-10,
2.0403093683955864e-11,
6.608289452293399e-13,
1.7390235400772094e-14,
3.661102189636231e-16,
6.021549654006965e-18,
7.457027435302749e-20,
6.541252136230485e-22,
3.6239624023437535e-24,
9.536743164062511e-27]plt.bar( krange, pmf, width=0.3 )
plt.xlabel("k")
plt.ylabel("p(k)")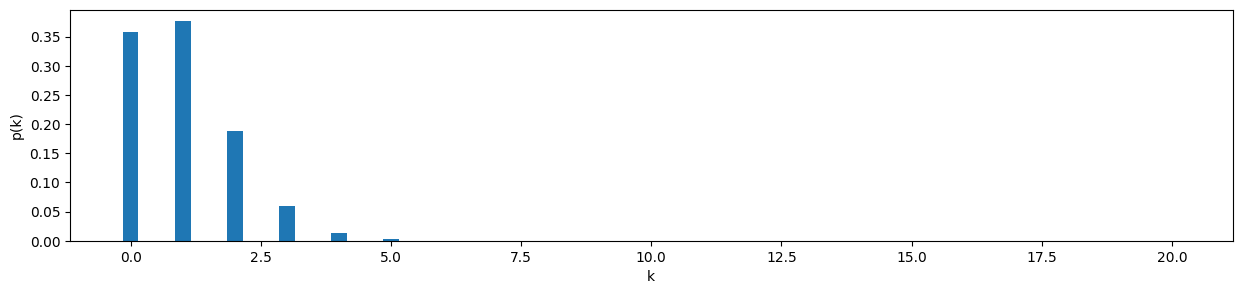
c) What is the probability that more than 3 pumps are defective on a production day? Use the cumulative distribution function (CDF).
3 or less pumps faulty:
stats.binom.cdf(n=20, k=3, p=0.05)0.98409847398023643 or more pumps faulty:
1-stats.binom.cdf(n=20, k=3, p=0.05)0.015901526019763581.6%!
d) On one day, 10 pumps are defective. What is the probability for this event and what do you suspect happened?
The probably for 10 pumps to be faulty is extremely small (one in every 100 million days..):
stats.binom.pmf(n=20, k=10, p=0.05)1.0802758002531833e-08Probably a machine is broken or a bad batch of input materials was used!
Exercise 4: Expectation of a PMF¶
Many count variables follow a Poisson distribution. The PMF of the Poisson distribution is
where (including 0) and is a parameter. Show that the expectation of the Poisson distribution is .
Hint: Use and introduce at an appropriate time. Finally, remember that .
This exercise was certainly not trivial and is not exam material. However we hope it served as a reminder about the mechanics in the expectation of a distribution and in particular of the Poisson distribution that we will use a few times within the coming weeks.
Exercise 5: Maximum likelihood estimator¶
This exercise anticipates what we will be studying in next week’s lecture and is a repetition of the frequentist maximum likelihood principle. Let’s consider the following problem: A coin has been tossed times, out of which it came up with heads times. What is a likely value for the coin’s probability of head ?
In your frequentist education, you have learnt that is a good estimator. In fact, it is the so-called maximum likelihood estimator for the binomial distribution that we want to derive in this exercise, in order to be better able to distinguish between frequentist and Bayesian inference.
The probability to measure a particular outcome (number of heads) can be computed with the binomial distribution:
In the maximum likelihood method, we look for the value of that is most likely to have produced our observation. In other words, we are looking for the value of that yields the maximum value for . To this end, one typically defines the likelihood function
in the domain of . Note that is not a probability distribution over (as it does not integrate to 1), for this reason Sir Ronald Fisher called it likelihood, as he needed another word than probability. In maximum likelihood, is maximized.
a) Use the first derivative by to show that the estimator maximizes for a given and :
For simplicity, assume that , i.e. .
Believe it or not, but it’s the same maths that yield as maximum likelihood solution for a linear regression with design matrix and outcomes .
b) Use Numpy and Matplotlib to plot for different values of and verify that the maximum is at
Hint: Use scipy.stats.binom.pmf() to compute .
Compute likelihood values:
from scipy.stats import binom
pi_values = np.arange(0,1.1,0.05)
probs = [binom.pmf(k=8, n=10, p=pi) for pi in pi_values]Plot:
plt.figure( figsize=(15,3) )
plt.plot( pi_values, probs, marker="o" )
plt.xlabel("$\pi$", fontsize=20)
plt.ylabel("$L(\pi|k=8)$", fontsize=20)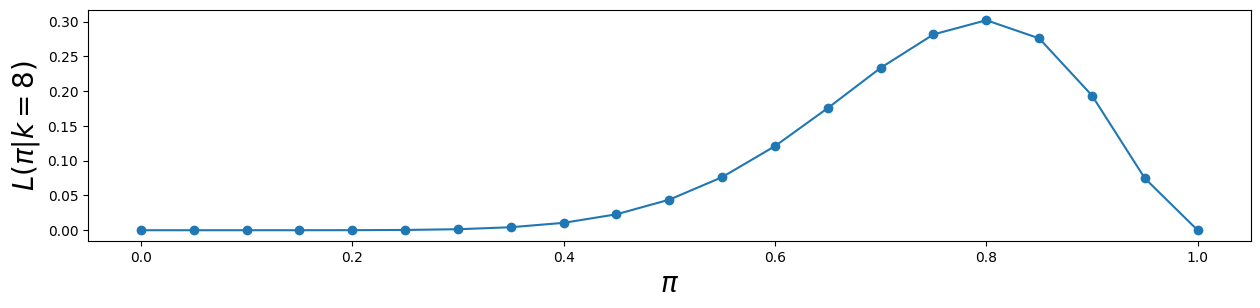
Exercise 6: Fighting terrorism¶
You work for the Swiss government and are in discussions with a security contractor who offers you a face detection software that could be installed at Zurich mainstation. The following are its performance measures:
Given that a person is registered as a terrorist, it finds them with a probability of 95%.
Innocent citizens are only recognized as terrorists with a probability of 0.01%.
Would you buy their system and employ it?
According to Wikipedia, 471’300 people walk through Zurich mainstation every day. Your system would flag 47 people as terrorists every day that would need to be arrested and investigated. With the very small rate of potential terrorists in Switzerland, almost all of the arrested people will be innocent. This would firstly be extremely expensive and secondly result in unpleasant consequences for the arrested people. Better not buy the system!
Exercise 7: Prison populations in Switzerland¶
In 2024, 70.1% of all prison inmates in Switzerland were not of Swiss nationality. One might be inclined to conclude that the majority of Switzerland’s inhabitants not holding the Swiss passport are criminal. Using Bayes’ theorem, show that this is not a correct interpretation and needs to be put into perspective. In particular, use the the following additional numbers:
There are 8.74 Million inhabitants in Switzerland.
About 27% of these 8.74 Million inhabitants are not of Swiss nationality.
About 6400 of these 8.74 Million inhabitants are currently in prison.
Given events (person is in prison) and (person is of Swiss nationality) compute, compare and interpret the probabilities and .
:
We need to employ Bayes’ theorem here:
Let’s go through the individual quantities bit by bit.
:
PP = 6400 / 8740000
PP0.0007322654462242563The probability that a randomly selected inhabitant is in prison is 0.073%! (one in 1366 people).
:
PnotS = 0.27
PS = 1-PnotS
PS0.73:
PnotSgivenP = 0.7
PSgivenP = 1 - PnotSgivenP
PSgivenP0.30000000000000004Compute result for via Bayes’ theorem:
PPgivenS = PSgivenP * PP / PS
PPgivenS0.0003009310052976396The probability that a person with Swiss nationality is in prison is 0.03% (one person in 3300).
:
:
PnotSgivenP = 1 - PSgivenP
PnotSgivenP0.7Compute result for :
PPgivennotS = PnotSgivenP * PP / PnotS
PPgivennotS0.0018984659716925162The probability that a person without Swiss nationality is in prison is 0.2% (one out 500). It is substantially higher than the probability for a Swiss national to be in prison (more than 6 times likely), but certainly still extremely small.
Exercise 8: Non-Invasive Prenatal Testing¶
Non-invasive prenatal testing (NIPT) is a blood test to determine the risk for a fetus to be born with trisomy 21, 18 or 13. The test has to be conducted between week 5 and 7 of pregnancy and is typically only applied when the first trimester screening (FTS or Ersttrimestertest ETT in German) is conspicuous.
In this exercise, we focus on NIPT’s abilities to detect the presence of the down syndrome (trisomy 21). The literature indicates a sensitity of 99.2% and a specificity of 99.91%. The prevalence of trisomy 21 depends on age: at age 20 it’s around 0.1% or less, at age 40 it increases significantly towards 1.4%.
You have just administered such a test and want to be prepared what it means to have a positive or negative test result.
a) Given the events : “Down syndrome present” and : “test result is positive”, formulate and compute the following probabilities of interest for a 40 year old woman:
that the Down syndrome is present given that the test turns out positive,
that the Down syndrome is present given that the test turns out negative,
Important probabilities:
(prevalence)
(sensitivity)
(specificity)
(false positive rate)
preval = 0.014
sens = 0.992
spec = 0.9991over marginalization:
PT = sens * preval + (1-spec) * (1-preval)
PT0.014775400000000013Probability that Down syndrom is present given test is positive:
PDT = sens * preval / PT
PDT0.9399407122649802If the test is positive, then in 93% the Down syndrome will actually be present. Compared to other examples, this is quite high!
Probability that Down syndrom is present given test is negative:
PDnotT = (1-sens) * preval / (1-PT)
PDnotT0.0001136796624850822If the test is negative, then chances that the Down syndrome is present nevertheless are extremely small, with a probability of 0.001%.
b) Answer the same questions for a 20 year old woman and explain the principal reason behind why NIPT is typically not used on 20 year old women.
Change prevalence and do the same computations again:
preval = 0.001PT = sens * preval + (1-spec) * (1-preval)
PDT = sens * preval / PT
PDnotT = (1-sens) * preval / (1-PT)
PDT, PDnotT(0.5245624239860366, 8.01515746428071e-06)The probabilities have changed significantly! Now the probability is only 52% that the Down syndrom is actually present given that the test is positive. This is extremely large, every second fetus would be a false positive in this test, possibly unsettling its future parents and leading them to administer further risky invasive tests, such as puncture of the amnion. The reason for this discrepancy has nothing to do with the test! Sensitivity and specificity stayed the same, but the reduced prevalence significantly increases the chance of false positives!
c) Using the same argument as in b), argue that the probability that you actually have Covid-19 given a positive Covid-19 self test was a time varying function between 2020-2022. What causes the variability in time?
The prevalence of Covid-19 changed throughout the pandemic (see e.g. here ) while sensitivity and specificity of the tests stayed roughly constant.
Exercise 9: Magic coin¶
You bought a magic coin from a wizard shop. Unfortunately, you have thrown away the instruction manual and cannot remember whether the coin is biased towards heads or towards tails. This is important, since you have to perform a magic trick in a few minutes. You call the company and they tell you that the coin comes in two models:
model 1 with (probability to show heads is 20% in the long run) is sold in 10% of the cases.
model 2 with is sold in 90% of the cases.
a) You throw the coin 5 times and it shows heads twice. What model do you think it is with your limited amount of data?
Hint: Compute the ratio of
where stands for your collected coin toss data, and use Bayes’ theorem and the binomial distribution.
With Python:
(binom.pmf(k=2, n=5, p=0.8) * 0.9) / (binom.pmf(k=2, n=5, p=0.2) * 0.1)2.2500000000000004You believe more than twice as much in the hypothesis that it’s model number 2!
b) Luckily, your magic trick worked and the coin showed heads as you predicted. At home, you have time for more flips. Interestingly, you flip the same ratio, just with ten times higher numbers: Out of 50 flips, you get heads 20 times. How much do you believe now that you have model 2?
ratio = (binom.pmf(k=20, n=50, p=0.8) * 0.9) / (binom.pmf(k=20, n=50, p=0.2) * 0.1)
ratio8.583068847656159e-061/ratio116508.44444444569You believe over 100’000 times more in model 1 than in model 2 now! The collected data have overruled your prior!
c) Argue why a frequentist magician would have failed at this task.
The frequentist magician would have estimated and favoured model 1. In his methods he has no way to introduce prior knowledge. On stage he would later have failed terribly!
d) Under what circumstance would you (the Bayesian magician) and the Frequentist magician have come to the same conclusion?
Hint: The frequentist cannot use the above ratio for decision making, but only
When are these two ratios the same?
If both coins would have been sold equally often, i.e. . Then
Exercise 10: Covid symptoms¶
In 2021, the Israeli Ministry of Health has publicly released data of all individuals who were tested for SARS-CoV-2 via PCR nasopharyngeal swab (see ‘covid_tests.csv’ in the exercise material on Moodle). The dataset lists the result of the covid test and the symptoms of the test subject. You are a data scientist (from 2021) and want to create a simple rule how individuals are to be prioritized for a test according to their symptoms (anticipating a shortage of the available covid tests).
a) Read the data from the CSV with pandas and perform the following additional actions: select only the columns ‘corona_result’ (result of the test) and the symptoms ‘cough’, ‘fever’, ‘sore_throat’, ‘shortness_of_breath’ and ‘head_ache’
filter out only ‘positive’ and ‘negative’ test results
replace ‘positive’ test results with 1 and ‘negative’ with 0
Read CSV file:
df = pd.read_csv("data/covid_tests.csv")
df.sample(5)Drop irrelevant columns, filter only positive and negative results and map them to 1 and 0 respectively:
df = df.drop(["test_date", "age_60_and_above", "gender", "test_indication"], axis=1 )
df = df[df.corona_result.isin(["positive", "negative"])]
df.corona_result = df.corona_result.replace({'positive': 1.0, 'negative': 0.0})
df.sample(5)(ignore the future warnings..)
b) Using the dataset, compute the conditional probabilities and
P(covid|cough):
df[df.cough==1].corona_result.mean()0.15837963965264246P(cough|covid):
df[df.corona_result==1].cough.mean()0.44801306477953184These probabilities are quite different! It is quite likely that you cough given that you have covid, but less likely that you have covid if you cough.
c) Use your pandas skills to compute all values for and
Hint: is easy to compute in a vectorized way using groupby(). The inverse probability is more difficult to do in a vectorized way, but it works if you compute the marginal probabilities () and multiply / divide them with according to Bayes’ theorem.
P(symptom|covid):
P_symptoms_given_covid = df[df.corona_result==1].drop('corona_result', axis=1).mean()
P_symptoms_given_covidcough 0.448013
fever 0.378266
sore_throat 0.103612
shortness_of_breath 0.079033
head_ache 0.151752
dtype: float64Marginal probabilities:
P(symptom):
P_symptoms = df.drop('corona_result', axis=1).mean()
P_symptomscough 0.151330
fever 0.077811
sore_throat 0.006881
shortness_of_breath 0.005634
head_ache 0.008667
dtype: float64P(covid):
P_covid = df.corona_result.mean()
P_covid0.053568570971355416Apply Bayes’ theorem to get P(covid|symptom):
P_covid_given_symptoms = P_symptoms_given_covid / P_symptoms * P_covid
P_covid_given_symptomscough 0.158590
fever 0.260415
sore_throat 0.806606
shortness_of_breath 0.751501
head_ache 0.937954
dtype: float64(the value for cough is the same one as we computed in b))
Which one would you rather use to prioritize individuals for covid tests, or ? List the symptoms from highest to lowest priority and argue that it makes a big difference what conditional probability you use:
Of course we want to sort out the invidiuals with the highest risk of suffering from Covid-19 and are therefore interested in P(covid|symptom). The order of priority is, from highest to lowest: head ache, sore throat, shortness of breath, fever and finally cough. The other probability P(symptom|covid) gives an almost inverted order and is not relevant for this problem!
Exercise 11: Sick trees¶
This is an exercise borrowed from the book Bayes rules!.
A local arboretum contains a variety of tree species, including elms, maples, and others. Unfortunately, 18% of all trees in the arboretum are infected with mold. Among the infected trees, 15% are elms, 80% are maples, and 5% are other species. Among the uninfected trees, 20% are elms, 10% are maples, and 70% are other species. In monitoring the spread of mold, an arboretum employee randomly selects a tree to test.
a) What’s the prior probability that the selected tree has mold?
b) The tree happens to be a maple. What’s the probability that the employee would have selected a maple?
Use marginalisation:
Pmaple = 0.8 * 0.18 + 0.1 * 0.82
Pmaple0.22599999999999998The probability to select a maple is 22.6%!
c) What’s the posterior probability that the selected maple tree has mold?
Pmold_given_maple = 0.8 * 0.18 / Pmaple
Pmold_given_maple0.6371681415929203d) Compare the prior and posterior probability of the tree having mold. How did your understanding change in light of the fact that the tree is a maple?
Knowing that it’s a maple raised the prior probability of mold from 18% to 63.7%. This makes sense, as maples are over-represented in infected trees and under-represented in healthy trees.
e) There is another way to compute the posterior probability using a simulation! Proceed in the following way:
Simulate 10’000 random trees and whether they have mold with
np.random.choice()according to the prior probability and store your result in a data frame.Assign a maple probability ( or from the description above to each tree according to whether the tree has mold or not.
For each tree, randomly sample whether it’s a maple using
np.random.choice()and .Compute by filtering out only maple trees and computing the ratio of them that has mold.
How close is the simulated posterior probability to the one computed in d) with Bayes’ theorem? Take some time and ponder why this simulation works. In the literature, this type of simulation is often called ancestral sampling, since it samples from two hierarchical levels.
Simulate 10’000 random trees and decide whether they have mold using P(mold):
sim = pd.DataFrame( {'mold': np.random.choice([0,1], p=[0.82, 0.18], size=10000)} )
sim.head()Assign the probability that it’s a maple using P(maple|mold):
sim['p_maple'] = sim.mold.map({0: 0.1, 1: 0.8})
simSample whether it’s a maple:
sim['maple'] = sim.p_maple.apply( lambda x: np.random.choice([0,1], p=[1-x,x]) )
sim.head()Compute posterior probability P(mold|maple):
sim[sim.maple==1].mold.mean()0.6460869565217391Why this works:
By sampling first whether the tree has mold from (mold) = 18% and then sampling for each tree whether it is a maple from (maple|mold) respectively (maple|), we have approximated a sample from the joint distribution (maple, mold). It is not difficult to compute the conditional probability (maple|mold) by filtering out just the trees with mold and the computing the proportion of maples.
- Pleninger, R., Streicher, S., & Sturm, J.-E. (2022). Do COVID-19 containment measures work? Evidence from Switzerland. Swiss Journal of Economics and Statistics, 158(1). 10.1186/s41937-022-00083-7