Generative Modelling
What generative modelling aims to do¶
Typical uses: density estimation, outlier detection, representation learning, and as a foundation for conditional generation
Generative modelling sits within unsupervised learning: we observe data without labels and learn hidden structure and dependencies.
Taxonomy of generative models¶
Explicit density models¶
Explicit density models define a parametric form for :
Tractable density¶
Autoregressive: factorize with the chain rule:
The Likelihood is exact and tractable.
Approximate density¶
Variational inference: optimize a lower bound (ELBO) when is intractable to integrate.
Flow-based: use invertible to map so that
Implicit density models¶
Implicit density models don’t give explicitly but can generate samples:
GANs learn a sampler via adversarial training.
Diffusion models learn to reverse a noising process; great sample quality but slow sampling.
Rules of Thumb¶
Variational Auto Encoders (VAE): Quick for sampling, easy to train, produce blurry images
GANs: Quick for sampling, hard to trian, produce high quality images
Diffusion models: Expensive to sample, easy to train, produce blurry images
Discriminative vs generative vs conditional generative¶
Discriminative models learn (classification, detection, segmentation). Labels compete for probability mass.
Generative models learn , where all possible inputs compete for mass (lets us reject unlikely inputs).
Conditional generative models learn ; for each label , images compete for mass within that class.
Bayes Formula¶
Prior: , initial probability of the model
Likelihood: , probability of the data given the model
Posterior: , probability of the model given the data
Marginal Likelihood / Evidence: , total probability of the data under all possible models
Bayes Formula for Generative Models¶
Prior i.e. Generative Model: , GAN, VAE, ...
Likelihood i.e. Discriminant model: , given the data how likely is a label
Posterior i.e. Conditional generative model: , probability of the data given a certain class
Marginal Likelihood / Evidence: , frequency of occurence
Shannon Entropy¶
The Shannon Entropy of a discrete measures inherent uncertainty:
Surprise (self-information) of an outcome:
rare outcomes ( small, blue regions) are high-surprise
common outcomes ( large, red regions) are low-surprise
Entropy (average uncertainty) of the distribution measures typical unpredictability across all outcomes:
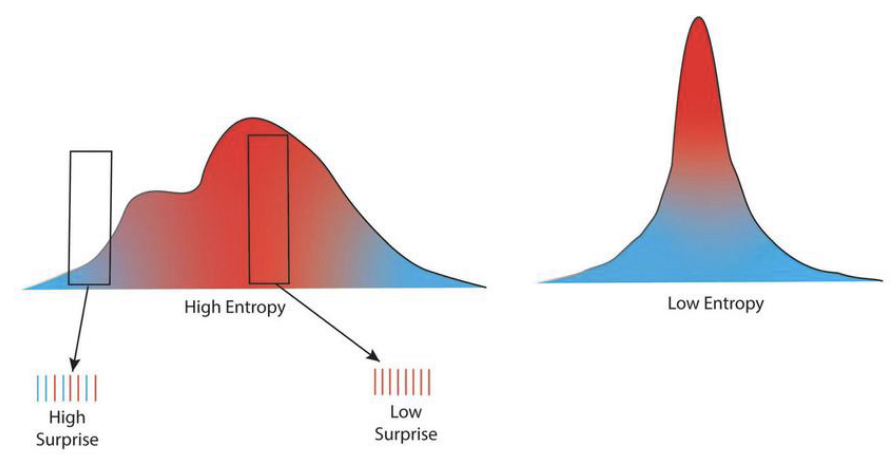
Left plot — High entropy: The distribution is broad/multimodal, so average unpredictability is high. A box over a blue, low-density region marks a high-surprise event; a box over a red, high-density region marks a low-surprise event.
Right plot — Low entropy: The distribution is sharply peaked; most mass sits near the center, so average unpredictability is low. Tail events would still be surprising, but they’re rare and contribute little to the average.
Cross-entropy¶
Cross-entropy between true and estimate :
It is commonly used as a classification loss (negative log-likelihood).
KL divergence¶
KL divergence (not a metric):
asymmetric and violates triangle inequality. Minimizing fits to .
Likelihood Function¶
Gaussian model and maximum likelihood¶
Assume are i.i.d. from .
Likelihood and log-likelihood:
Maximal Likelihood Estimate (MLE) (set derivatives to zero):
From single Gaussians to mixtures¶
A single Gaussian fails on multi-modal data. Increase flexibility with a mixture of Gaussians:
Direct MLE is hard because of the log-sum in .
Latent variables and EM for GMMs¶
Introduce latent assignments and work with responsibilities
Expectation–Maximization (EM) iterates:
E-step: compute for all using current parameters.
M-step: update parameters using soft counts :
Each iteration does not decrease the data log-likelihood and converges to a local optimum.
Variational perspective and the ELBO¶
For latent-variable models, the marginal likelihood is intractable. Introduce a tractable and use:
Thus ; maximizing the ELBO tightens the bound and implicitly makes approximate the true posterior.
Autoregressive density models (PixelRNN)¶
Use the chain rule to make likelihood tractable:
Architecture idea: an RNN maintains a hidden state to summarize the context .
Training: maximize log-likelihood (equivalently minimize cross-entropy). In practice use teacher forcing: feed the ground-truth prefix when predicting to avoid error accumulation.
Inference: sample sequentially from (stochastic; slower than parallel decoders).
Pros
Exact likelihood (good for model comparison),
High-quality samples with sufficient capacity.
Cons
Limited parallelism; slow sampling,
Potential bias from raster order; capturing global context can be challenging.